Batch Processing
There are three different types of systems:
- Services (online systems)
- Batch processing systems
- Stream processing systems.
Services are online systems that handle requests from clients and send responses back as quickly as possible. Batch processing systems take a large amount of input data, process it, and produce output data. These systems are typically not interactive and are run periodically. Stream processing systems, on the other hand, operate on events shortly after they happen and have lower latency than batch processing systems. Services prioritize response time and availability, while batch processing systems prioritize throughput, and stream processing systems prioritize low latency.
cat /var/log/apache2/access.log |
awk '{print $7}' |
sort |
uniq -c |
sort -r -n |
head -n 10 |
A log analysis job can be created to identify the 10 most popular pages on a website. This can be done with a simple program or using Unix commands (just like in the example above), which have the ability to handle large datasets and automatically parallelize processes across multiple CPU cores. Let's describe briefly what the above code does:
- The command cat /var/log/apache2/access.log retrieves the contents of the file /var/log/apache2/access.log, which is typically a log file containing information about access to an Apache web server.
- The awk command processes the output of the cat command and prints the seventh field (column) of each line.
- The sort command sorts the output of the awk command alphabetically or numerically, depending on the type of data.
- The uniq command removes duplicate lines from the output of the sort command and prints the count of each unique line before the line itself.
- The sort -r -n command sorts the output of the uniq command in reverse numerical order.
- The head command prints the first 10 lines of the output of the sort command.
Altogether, this series of commands retrieves the contents of the Apache access log file, extracts the seventh field from each line, counts the number of occurrences of each unique value, sorts the results in reverse numerical order, and finally prints the top 10 values. This could be used, for example, to find the 10 most popular pages on a website based on the number of requests for those pages recorded in the Apache access log.
The concept of connecting programs with pipes, became to be know as Unix philosophy, originated from the plumbing analogy and became popular among Unix developers and users. The philosophy consists of principles for designing and building software, including the idea that each program should do one thing well and that the output of one program should be the input to another. It also emphasizes the importance of building and testing software quickly, using tools to assist with programming tasks, and being willing to discard and rebuild parts of a program as needed. These principles were intended to encourage simplicity and modularity in software design.
MapReduce and Distributed Filesystems
MapReduce is a programming framework that allows large datasets to be processed in a distributed filesystem like HDFS (Hadoop Distributed File System). HDFS is based on the shared-nothing principle and consists of a central server called the NameNode and daemon processes running on each machine, which store and expose the file blocks stored on that machine. The NameNode keeps track of the locations of the file blocks and the file blocks are replicated across multiple machines for reliability. MapReduce works by reading a set of input files, breaking them into records, and calling a mapper function to extract a key and value from each input record. The resulting key-value pairs are sorted by key and passed to a reducer function, which collects all the values belonging to the same key and processes them. A single MapReduce job is similar to a single Unix process, as it does not modify the input and has no side effects aside from producing output.
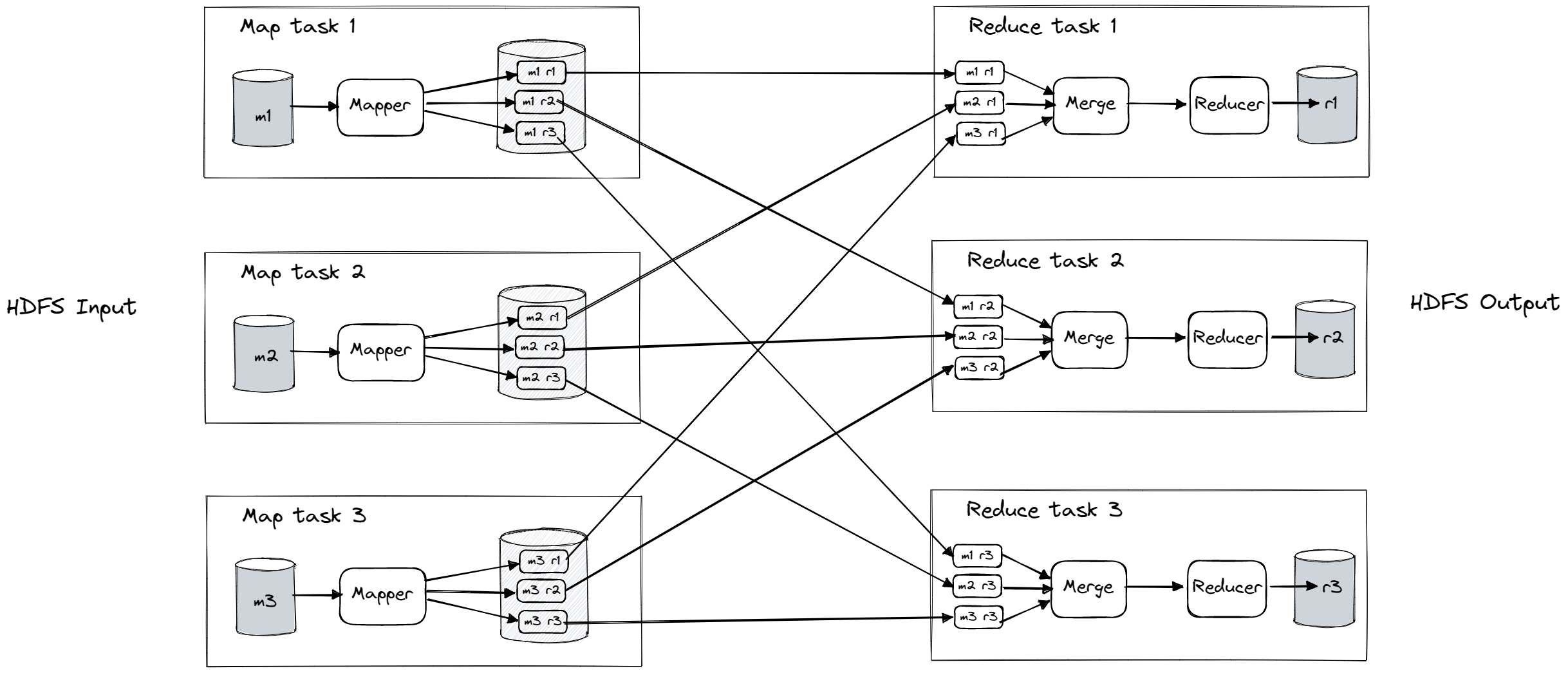
Hadoop MapReduce is a programming framework that allows large datasets to be processed in a distributed filesystem like HDFS. The parallelization of a MapReduce job is based on partitioning, where the input to the job is typically a directory in HDFS and each file within the directory is considered a separate partition that can be processed by a separate map task. The MapReduce scheduler tries to run each map task on a machine that stores a replica of the input file to increase locality and reduce network load. The application code for the map task is copied to the appropriate machine if it is not already present, and the map task reads the input file and passes one record at a time to the mapper callback, which produces key-value pairs as output. The reduce side of the computation is also partitioned, with the number of reduce tasks being configurable by the job author. The framework uses a hash of the key to determine which reduce task should receive a particular key-value pair and the reducers download the sorted key-value pairs from the mappers. This process of partitioning, sorting, and copying data partitions is known as the shuffle.
The reduce task in a MapReduce job takes the output files from the mappers and merges them together, preserving the sort order. This means that records with the same key produced by different mappers will be adjacent in the merged input for the reducer. The reducer is called with a key and an iterator that sequentially scans over all records with the same key and can use any logic to process these records and generate output. The output records are written to a file on the distributed filesystem, typically with replicas on other machines.
Reduce-Side Joins and Grouping
Joins are used to access records on both sides of an association, such as a foreign key in a relational model or a document reference in a document model. In a database, these associations are typically indexed to allow for quick access to the relevant records. However, MapReduce does not have the concept of indexes and instead performs a full table scan, reading the entire contents of the input files. While this can be inefficient for processing a small number of records, it is useful for calculating aggregates over large datasets and can be parallelized across multiple machines. When discussing joins in the context of batch processing, it is assumed that a job is processing data for all records in a dataset simultaneously, rather than looking up data for a specific record.
In a MapReduce job, the mapper extracts a key and value from each input record. For example if we have user and activity events database, the key could be user ID and the mappers extract the user ID as the key from both the activity events and the user database. The MapReduce framework then partitions and sorts the key-value pairs by key, so that all the activity events and user records with the same user ID are adjacent to each other in the reducer input. The reducer can then perform the join logic by processing all the records for a particular user ID at once and outputting pairs of viewed-url and viewer-age-in-years. This algorithm is known as a sort-merge join because the mapper output is sorted by key and the reducers merge the sorted lists of records from both sides of the join.
In a sort-merge join, the mappers and the sorting process ensure that all the necessary data for performing the join operation for a particular user ID is brought together in the same place. This allows the reducer to be a simple, single-threaded piece of code that can process records efficiently with low memory overhead. The MapReduce programming model separates the physical network communication of the computation from the application logic, unlike in typical database usage where the application code often handles fetching data from the database. MapReduce also handles all network communication and transparently retries failed tasks, protecting the application code from partial failures.
Grouping and joining are common operations in data processing, and they can be implemented using the MapReduce programming model by setting up the mappers to produce key-value pairs using the desired grouping key. The partitioning and sorting process will then bring together all records with the same key in the same reducer, allowing for efficient processing of the records. Grouping is often used for aggregating data, such as counting the number of records in each group or adding up the values in a particular field. It can also be used for sessionization, or collating all the activity events for a particular user session in order to understand the sequence of actions taken by the user. When implementing these operations in MapReduce, it is important to ensure that the records with different keys are distributed across different partitions in order to efficiently process the data.
The MapReduce programming model can be used to perform operations such as joining, grouping, and aggregating large datasets by bringing related records with the same key to the same place. However, if a key has a disproportionately large amount of data associated with it, known as a hot key or linchpin object, this can cause skew or hot spots, where one reducer must process significantly more records than the others. This can slow down the overall process and cause subsequent jobs to wait for the slowest reducer to finish. To alleviate this issue, techniques such as skewed joins, sharded joins, and two-stage grouping can be used to parallelize the work and distribute it among multiple reducers. These methods may involve replicating data or using randomization to spread the work across reducers.
Map-Side Joins
The map-side join approach is more efficient than a reduce-side join because it avoids the sorting and merging process. Instead, it relies on the assumption that one of the input datasets is small enough to fit in memory. The mapper loads this small dataset into memory and then processes the larger input dataset, using the data from the small dataset to perform the join operation. This allows the mapper to perform the join logic directly on the input data, without the need for sorting or merging. However, this approach is only suitable for certain types of data and join operations, and it requires careful planning to ensure that the small dataset is indeed small enough to fit in memory.
Map-side joins are useful when a large dataset is being joined with a small dataset, as the small dataset can be loaded into memory in each of the mappers. This is called a broadcast hash join, as the small dataset is "broadcast" to all the mappers and a hash table is used to perform the join. This method is supported by various tools such as Pig, Hive, Cascading, and Crunch. Alternatively, the small dataset can be stored in a read-only index on the local disk, allowing for fast random access without requiring the dataset to fit in memory. As pointed already map-side joins can be faster than reduce-side joins, as they do not require sorting and transferring data between mappers and reducers, but they are limited by the assumption that the small dataset can fit in memory.
If both datasets being joined are partitioned and sorted based on the same key, a map-side merge join can be used. This approach involves reading both datasets sequentially in order of ascending keys and matching records with the same key. It is possible to use a map-side merge join if the input datasets are already partitioned and sorted, which may have been done in a prior MapReduce job. However, it may be more efficient to perform the merge join in a separate map-only job if the partitioned and sorted datasets are needed for other purposes in addition to the join.
The Output of Batch Workflows
The output of a batch process is typically a transformed dataset that is used as input to another process or system, rather than being presented to a user as a report. Batch processing involves running a series of jobs to perform a specific task or set of tasks on a large dataset. The output of these jobs is often a transformed version of the original dataset, which can then be used for a variety of purposes, such as further analysis, data integration, or machine learning.
For example, a batch process might be used to extract data from multiple sources, clean and transform the data, and load it into a data warehouse or analytics platform for further analysis. Alternatively, a batch process might be used to prepare data for machine learning by extracting relevant features, normalizing data, and splitting it into training and test sets.
Batch processing is often used to perform tasks that are too complex or time-consuming to be performed in real-time, and it allows data to be processed in large quantities, often using distributed systems like Hadoop. The output of batch processing is generally not intended to be presented to users directly, but rather to be used as input for other systems or processes.
Philosophy of batch process outputs
Batch processing workflows using MapReduce can be used to build various outputs, such as search indexes, machine learning systems, and databases. These outputs can be used in web applications and other systems to provide data for analysis and decision making. It is important to write the output of batch processing jobs to a distributed file system rather than directly to an external database in order to avoid poor performance, system overload, and the need to handle partially completed jobs and speculative execution. By treating inputs as immutable and avoiding side effects, batch processing can achieve good performance and be easier to maintain, allowing for more efficient feature development and easier recovery from mistakes. The separation of logic and wiring also enables code reuse and better separation of concerns.
Beyond MapReduce
MapReduce is a programming model for distributed systems that is useful for learning and understanding distributed computing, but it can be challenging to use and may not be the most efficient choice for certain types of processing. To make it easier to use, higher-level programming models such as Pig, Hive, Cascading, and Crunch were developed as abstractions on top of MapReduce. However, these models still suffer from some performance issues and there are other tools that may be more efficient for certain types of batch processing.
Materialization of Intermediate State
In MapReduce, the output of one job is often used as input for another job. This is typically done by configuring the second job's input directory to be the same as the output directory of the first job, and then scheduling the second job to start once the first job has completed. This setup works well when the output from the first job is meant to be widely used within an organization and needs to be referenced by name and reused as input for various different jobs. However, when the output of one job is only ever used as input for a single job maintained by the same team, the intermediate files on the distributed filesystem are simply a way to pass data from one job to the next. In this case, the process of writing out the intermediate data to files is called materialization. In contrast, Unix pipes stream the output of one command incrementally to the input of another command using only a small in-memory buffer, instead of fully materializing the intermediate state.
MapReduce's approach of fully materializing intermediate state has several disadvantages compared to Unix pipes:
- A MapReduce job can only start once all the tasks in the preceding jobs that generate its input have completed. In contrast, processes connected by a Unix pipe are started at the same time, with output being consumed as soon as it is produced. This means that a MapReduce workflow may be slowed down by straggler tasks that take longer to complete.
- Mappers are often redundant, as they just read back the same file that was just written by a reducer and prepare it for the next stage of partitioning and sorting. In many cases, the mapper code could be part of the previous reducer, allowing reducers to be chained together directly without interleaving with mapper stages.
- Storing intermediate state in a distributed filesystem means that these files are replicated across multiple nodes, which may be unnecessary for temporary data.
Dataflow engines and Fault Tolerance
Dataflow engines like Flink offer an alternative to MapReduce for batch processing. They are particularly useful for workflows that involve many steps where intermediate state does not need to be fully materialized, as they allow for more efficient pipelined execution. While MapReduce jobs are independent from each other and input and output datasets are published to the distributed filesystem, dataflow engines allow for intermediate data to be passed between operators in a pipeline without being fully materialized. This can lead to faster execution and reduced storage requirements compared to using MapReduce. However, dataflow engines still rely on materialized datasets on the distributed filesystem for inputs and final outputs.
In order to handle faults in distributed batch processing systems, Spark, Flink, and Tez use different approaches. While MapReduce writes intermediate data to HDFS, these systems avoid doing so and instead track how data was computed and the ancestry of that data. If a machine fails and data is lost, it can be recomputed from available data sources. However, it is important for the computation to be deterministic in order for downstream operators to be able to handle any contradictions between old and new data. Spark uses the resilient distributed dataset (RDD) abstraction to track data ancestry, while Flink checkpoints operator state to allow for the resumption of operator execution in the event of a fault. Nondeterministic operators may require downstream operators to be killed and run again on new data.
Graphs and Iterative Processing
In the Pregel model, a graph is processed by defining a function that is called for each vertex in the graph. This function is passed all the messages that have been sent to that vertex, and the vertex can use this information to update its state and send messages to other vertices. This process is repeated until some completion condition is met, such as there being no more messages to process. The Pregel model is useful for processing graphs because it allows vertices to remember their state and only process new information, making it more efficient than MapReduce, which reads the entire input dataset and produces a new output dataset in each iteration. Pregel is implemented in tools such as Apache Giraph, Spark's GraphX API, and Flink's Gelly API.
High-Level APIs and Languages
The evolution of batch processing systems has led to improvements in programming models and execution efficiency. Higher-level languages and APIs, such as Hive, Pig, Cascading, and Crunch, have made it easier to program MapReduce jobs, while dataflow engines like Tez, Spark, and Flink have improved efficiency. These dataflow APIs use relational-style building blocks to express a computation, and can also be used interactively to allow for exploration and experimentation with data sets. The use of declarative query languages, like SQL, allows for the automatic selection of the most suitable join algorithms based on input properties. Despite the benefits of function callbacks in batch processing systems, the trend has been towards fully declarative query languages, like SQL, that allow for more efficient execution and easier integration with existing libraries and dependency management systems.
Summary
In this chapter, the topic of batch processing was discussed. The design philosophy of Unix tools such as awk, grep, and sort, and how it has been carried forward into MapReduce and more recent dataflow engines, was examined. The interface that allows one program to be composed with another in MapReduce is a distributed filesystem, while dataflow engines use their own pipe-like data transport mechanisms to avoid materializing intermediate state. The main problems that distributed batch processing frameworks need to solve are partitioning and fault tolerance. Different join algorithms were discussed for MapReduce, which are also used in dataflow engines. The programming model of distributed batch processing engines is restricted to stateless callback functions that have no externally visible side effects, allowing the framework to handle fault tolerance and provide reliable semantics. Batch processing is distinguished from other types of processing by reading input data and producing output data as a result, rather than processing individual requests. Stream processing involves processing data as it is generated, rather than in batch form, and requires a different set of tools.