Key-Value Store
Pretty common system desing question, but as you will see the whole system could be broken down into theoretical concepts we have already researched. Generally you should always have this concept ready in your arsenal since they can be utlized on any distributed system problem. So we're designing two simple operations:
put(key,value)get(key) -> value.
Those are all of our functional requirements, for the non-functional requirements we have:
- High availability
- High scalability
- Low latency
- Big data
- Consistency
- Fault tolerant.
Since we can have unlimited data storage requests a single server would quickly become overloaded, leading to problem of designing distributed key-value store. But before we move to solving issues with distributed systems, let's show how we can design a simple class that would serve as key-value store that could be run on a single server.
class LRUCache {
private class ListNode {
int val;
int key;
ListNode next;
ListNode prev;
ListNode(int x) {
val = x;
next = null;
prev = null;
}
}
int capacity;
int numberOfNodes;
Map<Integer, ListNode> map;
ListNode head, tail;
private void removeNode(ListNode node){
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void addToHead(ListNode node){
node.next = head.next;
head.next.prev = node;
head.next = node;
node.prev = head;
}
public LRUCache(int capacity) {
this.capacity = capacity;
numberOfNodes = 0;
map = new HashMap<>();
head = new ListNode(-1);
tail = new ListNode(-1);
head.next = tail;
tail.prev = head;
}
public int get(int key) {
if(!map.containsKey(key)) return -1;
ListNode node = map.get(key);
removeNode(node);
addToHead(node);
return node.val;
}
public void put(int key, int value) {
ListNode node = map.getOrDefault(key, null);
if(node != null){
removeNode(node);
node.val = value;
addToHead(node);
}else{
node = new ListNode(value);
node.key = key;
addToHead(node);
++numberOfNodes;
map.put(key, node);
}
if(numberOfNodes > capacity){
map.remove(tail.prev.key);
removeNode(tail.prev);
--numberOfNodes;
}
}
}
This is java implementation of Least Recently Used (LRU) cache in which we evict the least recently used element when we go over the cache/key-value store capacity.
We have constant time complexity since we have implemented fast lookup using the hashmap which also needs c space (where c is maximum capacity). So we need a fast lookup since it's cache so your first hint should be to use hashmap, we also need a way to evict least recently used keys from the cache, so we need a fast deletion and insertion to the front of the container (marking the key recently used) and also deletion from the back of the container (least recently used range of keys). It turns out the double linked list enable use to have fast retrieval of the last element, and fast deletion and insertion (since there is no shifting required as we have for example in array as continuous data storage). We utilize two sentinel (fake) pointers head and tail so we can easily put the new nodes to the head of the list and also delete elements from the end of the list. On get we try to find the node matching the key, if we don't find it we return -1, otherwise we return the value stored at that node which is mapped from the requested key. But also since that key is now recently used we have to place it at the front of the list, by first removing from it's current place and placing it as new head of the list. On put we first check if the node with the key is already in the map, if it is we update it's value and again repeat the process of shifting it to the front of the list. If however we don't have a node mathing the required key, we create new node while aslo remembering it's key and put the pair key, node to our hashmap. Finally, we also check if we're over capacity for our LRU and then we evict the last node in the list tail.prev by removing it from the list and also using it's stored key to remove it from the map, so that we return -1 on the next get for that specific key.
Distributed key-value store
First topic that you should discuss with the interviwer when it comes to distributed systems is the CAP theorem. The CAP theorem, which states that a distributed system can only have two out of three desirable properties (Consistency, Availability, and Partition tolerance), is often presented as a choice between two properties. As said we will be covering this problem with concepts already learned, so to start check The CAP theorem. Now to fulfill our non-functional requirements since we have a distrubuted system we have to (as always) partition and replicate. For partition you will often hear about Consistent hashing which places first the servers on a imaginary circle which is made of a hash range (e.g. 0...100, each hash will fall into this range, of course in real systems we would have much larger range) by hashing their IP addresses, and then for each key we hash we will place it on the circle too. How to find which server does the key belong to? We just go clockwise on our circle until we hit the first server node. Since we can get into situation where one server holds most of the keys because of non-uniform distribution of the keys, to decrease the standard deviation for number of keys hold by each server we can just increase the number of partition hold by each server (you can think of partition as part of the circle, subrange of the whole range). Adding and deleting nodes is also easy since we don't have to reshift the whole sets of keys, we just have to reshift (change the server who owns them) subset of keys. Note that consistent hashing is nothing more than Partitioning proportionally to nodes which we already discussed in Rebalancing Partitions. One should also note that it's possible to have domino failure, where one server gets overloaded and goes down leading to rehashing of the keys to another healthy server which could then overload this server too leading to a chain reaction, but with some smart spliting of the keys that need to be rehashed we can prevent this situation.
Now we can uniformly distribute keys onto several servers leading to fulfillment of high scalability and big data requirements. Since we don't want to lose the whole subset of keys when the server holding it goes down we have to employee replication. But including replication while it increases availability and also decreases latency (since we can have clients read from close-by replicas) it leads to problem of consistency. To read more about replication, leaders and followers and common consinstency issues read Replication. Now how do we cope with consistency issues? We had already talked about Quorum Leaderless Replication which could be configured to favor writes or reads or even strong consistency. To learn more about what strong consistency is check out Consistency and Consensus. How can we cope with write conflicts preventing two replicas from completely diverging from common state? You got it, back to the fundamentals Handling Write Conflicts.
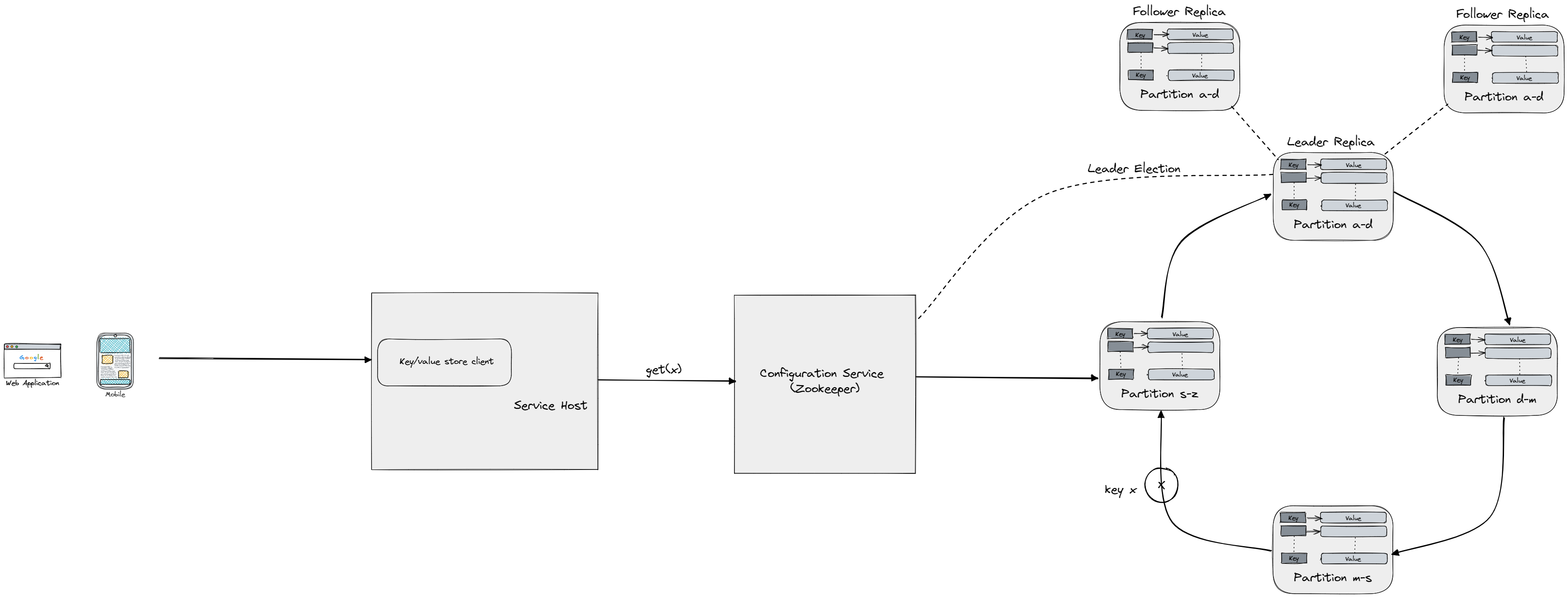
So now we move to not "happy-path" scenario in which some of server nodes go down. We can assume two models:
- crash-stop the server is gone forever
- crash-recovery where nodes may crash and then start responding again after some unknown time.
Since it's crash-recovery is more useful of the two, we would be focusing on it. So the first questions is how do we know if the server is down? The most ussual approach is to have a heartbeat check, in which each node periodically increments the heartbeat counter (saying essentially I'm still alive), now there are two options on where to hold these counters. We can have a centralized entity (configuration service like Zookeeper) which will be responsible to track the heartbeats, but now that entity/component could be single point of failure and should be replicated for fault tolerance which ussually most off the shelf solutions like Zookeeper do (leader-follower replication, with Raft like leader election). Another option is to use gossip protocol, where each node send the info (heartbeats) to few neighboring nodes which then send it to their neigbors until we have full (vertex/node) cover. We can also have anti-entropy in which we constantly repair the replicas by comparing their state and updating it so they converge to the same state. It would be impractical to check the real data values when comparing the states of replicas, to cope with this problem we can use Merkle tree which are trees that have data values as their leaves, and then each (non-leaf) internal node is a hash of it's children. To check if the two replicas have the same state we just check the root of their respective trees, if not we recursively check left and right subtree to find the mismatch and we repair only the keys that are hold in leaves that are descendants of node where we found the mismatch.
Since we could experience performance degradation is important to spend some time discussing telemetry. We should be collecting logs entries for each of the request and track if the request was cache hit or miss, CPU/memory utilization, number of faults, request time and so on, so we can investigate further what went wrong in our system.