Tiny URL
Tiny URL is a service with a straighforward functionality, it takes some long URL and it shortens it keeping the mapping between long and short version for redirection purposes. For the non-functional requirements we have:
- high scalability (the service should grow with the load)
- high availability (preventing situation where we cannot redirect user using short link to the original mapped long URL)
- fault tolerant (one component fault shouldn't lead to total system failure)
Let's quickly do the back-of-envelope calculation: With 50 million URLs generated daily, the write operation rate would be 580 URLs per second (50mm / 24 / 3600). Assuming a read-to-write ratio of 10:1, the read operation rate would be 5,800 URLs per second (580 x 10). Over a 10-year span, the service would need to support 182.5 billion records (50mm x 365 x 10), with an average URL length of 100 bytes, resulting in a total storage requirement of 182.5 Terabytes (182.5 billion x 100 bytes x 10 years).
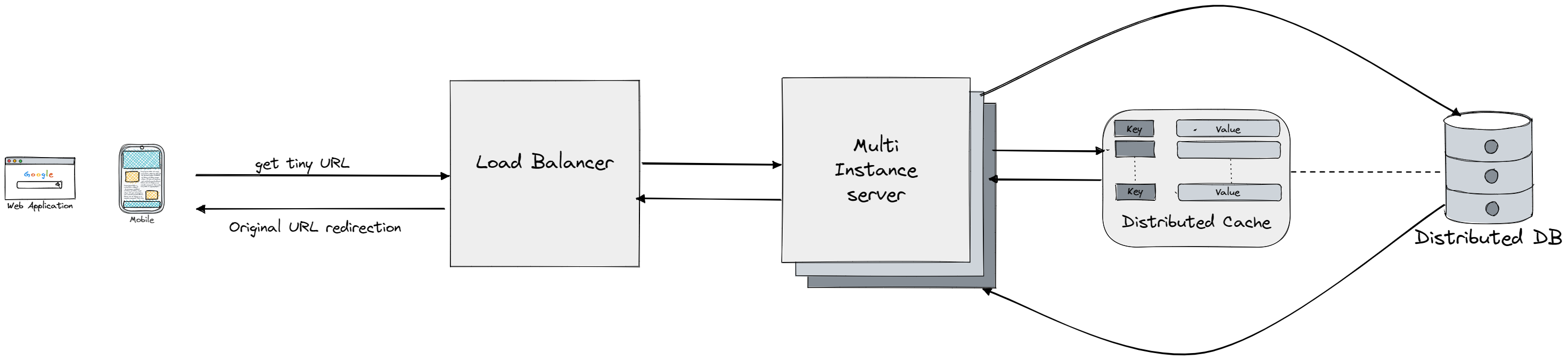
The most natural data structure of choice for this problem would be a hashtable mapping from short url to the long one. We would have two open endpoints one for actually creating (POST) the mapping (put in hashtable) and the other for redirecting from the short version of the URL to the original URL (GET with 301 or 302 status codes). A 301 redirect indicates a permanent move of the requested URL to the long URL. This results in the response being cached by the browser, so subsequent requests for the same URL will not be sent to the URL shortening service, but rather directly to the long URL server. On the other hand, a 302 redirect shows a temporary move of the URL to the long URL, causing subsequent requests to be first sent to the URL shortening service, before being redirected to the long URL server. Both can be used but since we want to store logs and do additional analysis on most visited links we want our TinyURL servers to be pinged for each request.
Our hashtable must hash the long URL to a unique hash value, and create mapping between hashvalue which will be used to create our tiny url to map back to the original URL. So we have to define a hash function that will satisfy this requirements. Let's assume that the hash will only contain alphanumerical characters so in total we have 26*2 (lowercase and uppercase letters) and 10 digits leading to 62 characters to choose from. Now we could use popular hash functions like MD5 or SHA-1, but all of them will produce longer string that we actually need to represent uniquely 182.5 billion records in 10 years period. We could only take first few characters (example first 7 characters so we can represent more than 183 billions records), and then check for collisions which could lead to many request to database to check if the hash already exists. But if we had a unique idenficator for each row we put in our database (database row will only contain short and long/original version aka our mapping) we could take it as input to our hash function. Since we have 62 options we can convert the ID to base 62 and use it as our hash output, since each ID is unique it's representation in base 62 will be unique too. Now since we will use a distributed database (deep dive on Aurora example Amazon Aurora) we now have to solve a problem of generating unique ID in distributed database. We can use divide-and-conquer approach by grouping the bits of unique ID, one group will be the actual timestamp (starting from some epoch), then one for datacenter, one for machine, and least group of bits for generating different ids from the same machine. If we leave enough bits (say x) for the last group of bits one machine could produce 2^x different IDs per millisecond (since each millisecond the first group of bits will be changed because of timestamp). To read more about clocks in distributed systems check the following section Unreliable Clocks.
Now that we have hash function we can check out the write and read path. For write path we have the following sequence:
- There is POST request to our service containing long URL
- Our service checks if the long URL is in the database and if it's just returns the short version
- If the URL is new, we generate a new ID, convert it to base 62 and create a row in database
- We return the short version to the user.
Note that for both read and write path we will have a cache layer, for read path it's obvious that we can utilize locality and frequency (most visited links will continue to be frequently requested). But for the write path we could also have a inverse mapping, from long to short version, so if there is a post request with a long URL we can just check if we already have it in cache before hitting the database. The read path will go as follows:
- We will have a load balancer in front of our servers so we can distribute the load
- The user sends a GET request with short URL, and we first check the cache. If the record is there we just return the long URL
- If we don't have the record in database we check the database, and return it if we find it. If not the user might have requested invalid URL
- We return the long/original URL to the use.
To achieve a functional system we could reuse all the components we already discussed that fulfill all of our non-functional requirements:
- Amazon Aurora as distributed database
- Facebook Memcached and Key-Value Store
- Rate Limiter for limiting the requests on our servers.
Now that we have designed the basic system we can cover another scenario of actually doing analytics on our service like the most visited links, click through rate and similar. To solve this we will be designing solution to "top k problem" in the following section. Let's say we're interested in top 200 most visited tiny URLs, if we had a single database we could just aggregate (count) and return the result, but since we're dealing with a distributed system and both distributed cache and database and high load this renders this approach useless. So we turn to big data processing approaches such as MapReduce (more on it in Batch Processing), but since we want close to real time data processing we have to utilize Streams (more on Stream Processing). Since we're doing 302 redirect all the request will be delivered to our services and we will store each request to certain URL as a click event and we apply our solution to "top k problem" to these events.
If we're talking about the algorithm we could use the frequency map, where the key will be the tiny URL and the value will be the total occurence of that tiny URL in the event database/logs. We can then sort the keys by decreasing frequency and take first k elements which would leave us with O(nlogn) time complexity and linear space complexity required for the frequency map. If we assume the k will always be much smaller than n (which is logical thing to assume) we could decrease the time complexity to O(nlogk) using a minheap each time the size of the heap goes over k we just discard the top element leaving k largest elements in the heap after n heap add/poll operations. Now if we scale from single machine to distributed system with multiple servers doing the counting we could handle the load for our service, note that each of the processors (service doing the counting, using the minheap algorithm described before) is only dealing with a set of keys/URLS (partition). Since we have multiple processors to get the final ouput we will have to combine the lists, sort them and extract the top k records. But since the processors already ouput the sorted (by frequency) of URLs we can merge the lists using maxheap in O(nlogn) (below algorithms shows how to do it on linked list, but with minor modifications we can do the same on arrays, by keeping the array of last index used for each of the lists and inserting a tuple of element value with array index into heap):
public ListNode mergeKLists(ListNode[] lists) {
ListNode dummy = new ListNode(-1, null), iter = dummy;
PriorityQueue<ListNode> pq = new PriorityQueue<>((a, b) -> b.val - v.val);
for(int i = 0; i < lists.length; ++i){
if(lists[i] != null) pq.add(lists[i]);
}
while(!pq.isEmpty()){
ListNode node = pq.poll();
iter.next = node;
if(node.next != null){
pq.add(node.next);
}
iter = iter.next;
}
return dummy.next;
}
As you can see these operations resemble the operations we would do in a MapReduce job, we would emit the key and count for each of keys (URLS), and then reduce them to single sorted list. But with with MapReduce come problems such as dealing with hot partitions, adding a processing/mapper service, we also have to store replicated copies of partition to prevent losing the data. Also we should make a certain partition as close as posssible to the mapper service responsible for it (ussualy on the same host/machine). Also note that we can't just have materialized view for a certain period of time (example 1h) and use them to calculate top k for longer period say one day - 24h, since the top k URLs stored for each hour might not be necessarily the top URLs for the whole day. But before moving to MapReduce approach first we should ask ourselves is there any probabalistic based methods/data structure that would allow us quick calculation of the top k URLs albeit with some accuracy loses. One data structure that would allows us to do that is called Count-min sketch which is probabilistic data structure that serves as a frequency table of events in a stream of data.
You can think of Count-min sketch as two dimensional array where for each row we have a different hash function. So when we add the first URL link, this data structure will calculate for example 5 different hashes (one for each row) for this URL and it will increment a column corresponding to the hash for each row. Ussually we might have collisions if the hash function produces that same output for two different inputs which will increment the same column, for that reason when we query for the total count for one key we take the minimal value from corresponding column in each row. That's the reason why we need to have multiple hash functions, to prevent returning value we got as byproduct of hash collisions. Note that in our case since we have picked a specific hash function to prevent collisions we shouldn't face this problem. This data structure helps us to eliminate the need for hash table, since it's always limited in size (limited number of rows/hash functions).
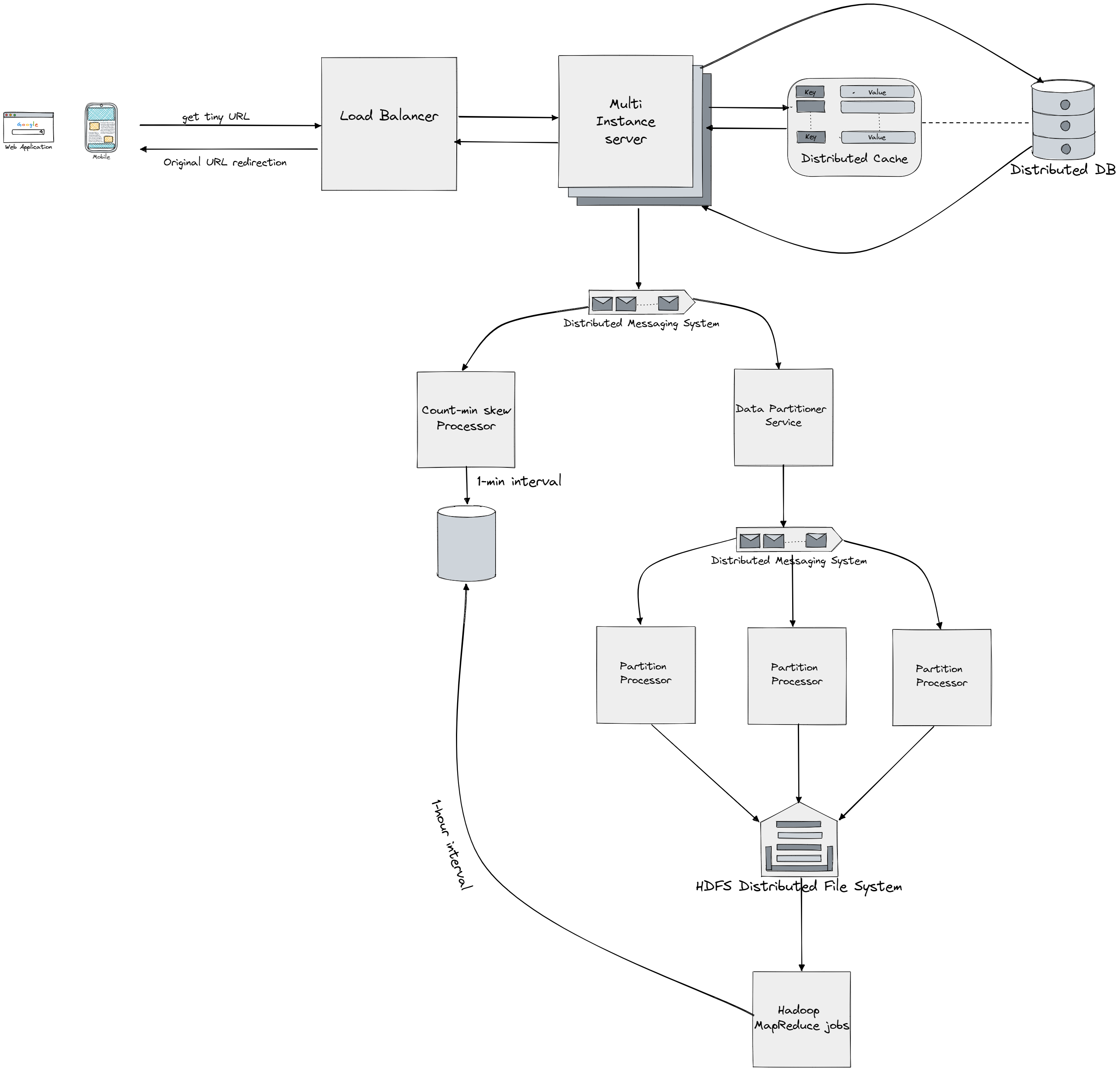
On our servers we will implement a background process that reads data from the logs, performs initial aggregation, and sends the data for further processing. The data will be stored in a limited-size buffer, and when the buffer is full, the data will be flushed. If the buffer is not full for a specified period of time, flushing can be based on time. There are also other options for processing the data, like aggregating on the fly or sending information about every URL click for further processing. The data will be serialized into a compact binary format to save on network utilization if the request rate is high. The initially aggregated data will then be sent to a distributed messaging system like Apache Kafka. The processing pipeline will be split into two parts: fast path and slow path. On the fast path, a list of the top k URLs will be calculated approximately and be available within seconds. On the slow path, the list of URLs will be calculated precisely, with results available within minutes or hours, depending on data volume. The fast path will use a service called processor that creates a count-min sketch and aggregates data, while the slow path will use MapReduce to dump data to a distributed file system (while with partitioner we can fit the partitions so that we have "data close to computation" where each mapper will sit on the same server as the data it operates on), calculate frequency counts and top k list, and store the data in the database. This data processing pipeline helps to decrease the request rate, starting with millions of user requests on servers pre-aggregating data, reducing the number of messages sent to Kafka, further aggregating data on a smaller Fast Aggregator cluster, and finally storing only a small fraction of the initial requests in the database. For retrieving the data for 1-min interval we can request it from the fast path stored in database (if we have for 2mins we just add the count-min tables for both minutes), this will of course get us a the data fast although with some accuracy loss. When we want a summary of top k URLs for 1h time period we can request it from the slow path result stored in database, but if we want to combine results we got in few hours we would have again some accuracy loss. It's important to note that's not a new idea, since this kinda of arhitecture combining slow and fast paths (stream and batch processing) is called The Lambda Architecture. Finally we could have used another probabalistic approach like Frequent Algorithm, Lossy Counting, SpaceSaving and Sticky Sampling.