Cloud Storage Service
Cloud storages like Google Drive and Microsoft OneDrive have gained immense popularity. In this chapter we will desing a file storage system with a focus on synchronization between different devices (or similar problem of live collaboration).
As you design platforms like Microsoft OneDrive and Google Drive, here are some of the key functional requirements that should be included:
- File upload and download: The platform should allow users to upload and download files from their devices to the cloud.
- File synchronization: The service should support file sync across all devices to ensure that users have access to the latest version of their files at all times.
- Notifications: The platform should send notifications to users whenever there is an update or addition to their files, to keep them informed and in control.
- Multiple device support: The service should be accessible from a variety of device types, including computers, smartphones, and tablets, to provide users with seamless access to their files no matter where they are.
In addition to the functional requirements, there are several non-functional requirements that are crucial for the success of the Google Drive platform:
- Reliability: The service should be highly reliable and ensure that users' files are securely stored in the cloud and accessible when needed.
- Fast synchronization speed: The file sync process should be fast and efficient, ensuring that users' files are updated in real-time across all devices.
- Scalability: The platform should be designed with scalability in mind, to ensure that it can easily handle an increasing number of users and a growing volume of files.
- High availability: Google Drive should have a high availability design, meaning that the service should be up and running with minimal downtime, to ensure that users can access their files whenever they need to.
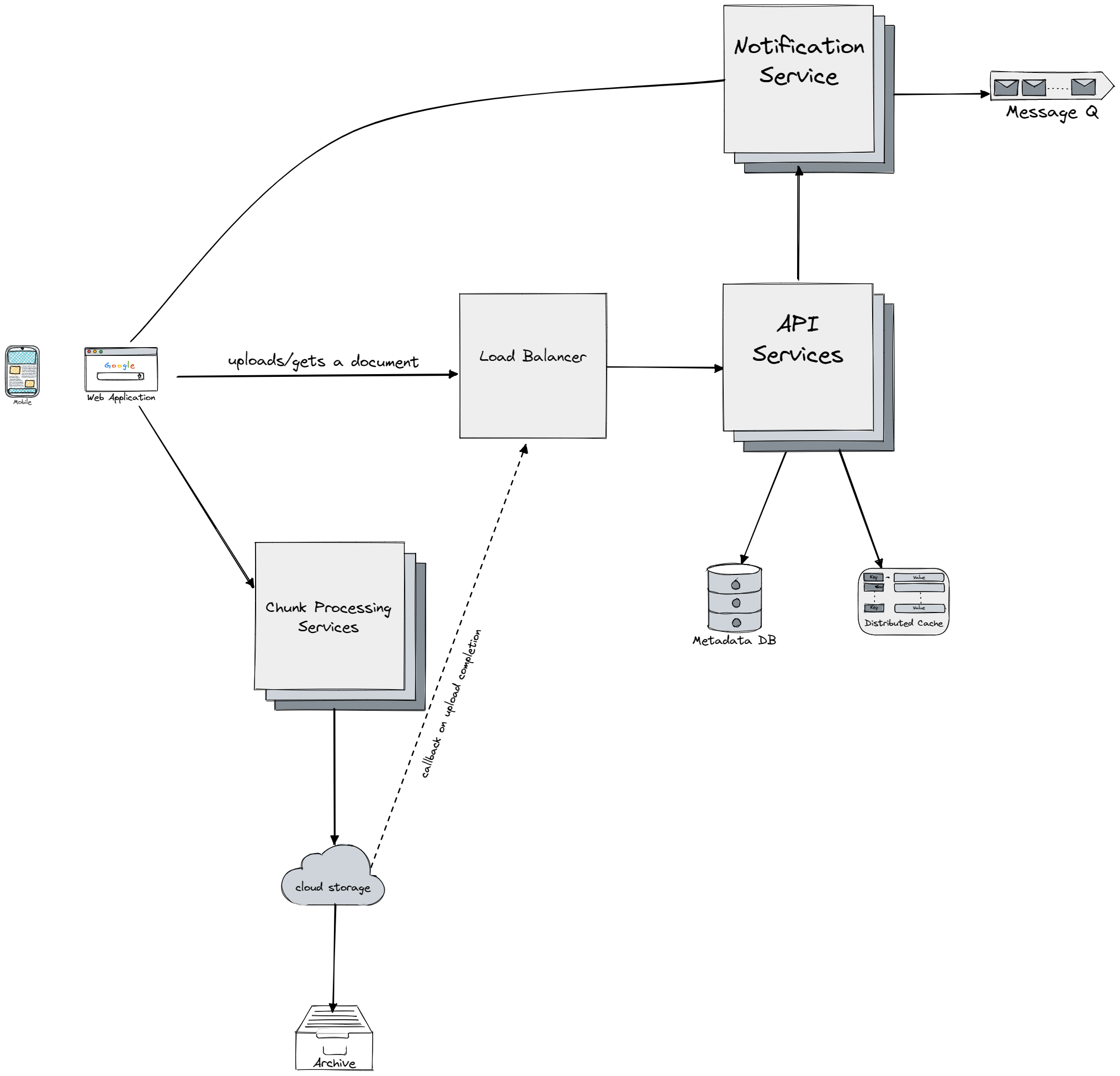
In order to optimize the performance and reliability of the cloud storage platform, the following components should be considered:
- Load Balancer: To distribute network traffic, a load balancer should be added. This will ensure an even distribution of traffic and will automatically redirect traffic if a API server fails.
- API Services: Once the load balancer is in place, additional API service instances can be added or removed as needed to accommodate changes in traffic.
- Chunk Processing Services upload chunks of data to the cloud storage. By splitting data files into chunks, each with a unique hash value, they can be stored efficiently in the cloud. The chunks are treated as independent objects and are stored in Cloud file storage like Amazon S3. To reconstruct a file, the blocks are reassembled in a specific order. To minimize network traffic during updates, optimizations such as delta sync (sending only modified blocks instead of the entire file) and compression can be used.
- Metadata Database: To avoid a single point of failure and ensure availability and scalability, the metadata database should be relocated and set up for data replication and sharding. A relational database is chosen for its native support of ACID for strong consistency. Check Amazon Aurora chapter for more information on how to design distributed databases
- Cloud File Storage like Amazon S3 is used for file storage, and files are replicated in two separate geographical regions to ensure availability and durability.
- Archive Storage for storing inactive data, a cold storage system should be employed.
- Long Polling: To receive notifications of changes to a file, each client will establish a long poll connection to the Notification Service. When changes are detected, the client will close the connection and retrieve the latest updates. The connection will be immediately reopened after receiving the response or reaching a connection timeout. We also keep a queue of message to store the notifications for the users who are currently offline, so once they get back online the batch of notification is sent to them.
Collaboration and conflict resolution
In an ideal world each write would go through one designated database server and we would have a total order of changes to a document or file. But in reality we will have situation where two devices have two different states of files (writting locally withoug going through master-writter database), we have to keep the changes from both devices or both users (live collaboration), which leads to a need of effective conflict resolution.
While it is possible to use a linearizable replication approach for collaboration, it would result in slow performance, as every read or write operation would require communication with multiple (quorum of) replicas. Additionally, it would not be feasible for devices that are offline. For better speed and robustness against network disruptions, most collaboration software employs an optimistic replication method, which provides strong eventual consistency.
Conflict resolution arises when multiple concurrent changes to the same object must be combined into a single final state. Conflict-free replicated data types (CRDTs) are a category of algorithms that handle such conflict resolution. A CRDT is a replicated object that a program interacts with through the object-oriented interface of an abstract data type, such as a set, list, map, tree, graph, counter, and so on. To update a value for a specific key, a globally unique timestamp is generated to identify the operation. This can be done using a Lamport timestamp, which is a common choice. The updated information, including the timestamp, key, and new value, is then broadcasted as a message. When the message is received, the local copy of the values is checked for an entry with a higher timestamp for the same key. If one exists, the message is disregarded as the value with the higher timestamp takes precedence. If there is no entry with a higher timestamp, the previous value (if any) is removed, and the new (timestamp, key, value) triple is added to the set of values. This process resolves concurrent updates to the same key using the last-writer-wins (LWW) method.
We're using reliable broadcast for replication without the need for total ordering of messages. It is considered an operation-based (as opposed to state-based) conflict-free replicated data type (CRDT), as each broadcast message consists of a description of an update operation rather than the state of the data. The algorithm allows for updates to be made even without network connectivity as the sender of a reliable broadcast can immediately deliver a message to itself and send it to other nodes at a later time. Despite the possibility of messages being delivered in different orders on different replicas, the algorithm guarantees strong eventual consistency because the function for updating a replica's state is commutative.
Instead of sending each individual update, the entire state of the values can be updated and then broadcasted. Upon receiving this message, the other replica's state is merged with the broadcasted state using a merging function. This merging function evaluates the timestamps of entries with the same key and keeps the entry with the greater timestamp. This method of broadcasting the entire replica state and merging it with the other replica's state is referred to as a State-based CRDT. The state-based CRDT approach has a drawback in that the size of broadcast messages is typically larger compared to the operation-based approach. On the other hand, it offers the advantage of being able to handle lost or repeated messages effectively. So long as two replicas eventually exchange their most recent states, they will converge to the same state, even if some earlier messages are missing. Additionally, duplicated messages do not pose a problem as the merge operation is idempotent. As a result, state-based CRDTs can utilize unreliable, best-effort broadcast, whereas operation-based CRDTs require reliable broadcast, and some even require causal broadcast. It should also be noted that state-based CRDTs are not limited to replication systems that use broadcast, as other replication methods like quorum write algorithms and anti-entropy protocols can also utilize CRDTs for conflict resolution.
In a Google Doc type of file editing live collaboration, keystrokes are immediately applied to the local copy of the document in a user's web browser, without the need for syncing to a server or other users. This can lead to temporary divergences in documents if two users are typing at the same time. The system must then ensure all users converge to the same view of the document. In this scenario, a collaboratively editable text document is considered as a list of characters, where each user can insert or delete characters at any index in the list. Let's say both users A and B start with the same document "BC", but A inserts "A" at the beginning and B inserts "D" at the end. After merging their edits, the final document should read "ABCD". However, when B sends the operation "insert(2, D)" to A, and A inserts the character "D" at index 2, the result is "ABDC". This is because at the time of B's operation, index 2 referred to the position after "C", but A's concurrent insertion at index 0 increased the index of all subsequent characters, making the position after "C" now index 3. To address this, a node keeps track of the history of operations it has performed and uses a transformation function T to modify an incoming operation if it is concurrent with one or more local operations. The transformed operation ensures that the intended effect of the original operation is still achieved. For example, if op1 = (insert, 2, "D") and op2 = (insert, 0, "A") then the transformed operation is T(op1, op2) = (insert, 3, "D") because the original insertion op1 at index 2 now needs instead to be performed at index 3 due to the concurrent insertion at index 0. On the other hand, T(op2, op1) = op2 returns the unmodified op2 because the insertion at index 0 is not affected by a concurrent insertion later in the document.
An alternative to the need for total order broadcast in operational transformation is using a CRDT for text editing. Instead of using indexes to identify positions in the text, which necessitates operational transformation, text editing CRDTs assign a unique identifier to each character. This identifier remains constant even when characters are inserted or deleted around it. each character is assigned a rational number in the interval (0,1), with 0 representing the start of the document, 1 representing the end, and the numbers in between identifying the characters in ascending order. To insert a new character between two adjacent characters with position numbers i and j, the new character is assigned a position number of (i+j)/2, which always falls between i and j. However, if two different nodes insert a character at the same position, the same position number may be generated, so the node's ID is used to break ties for characters with the same position number. The current document is obtained by broadcast, where an insertion message with a particular position number is broadcast, and then other replicas add that character and sort the set of characters by position number. The use of causal broadcast, as opposed to reliable broadcast, in this algorithm ensures that if a character is deleted, all replicas process the insertion of the character before processing the deletion. This is necessary because the insertion and deletion operations of the same character do not commute. However, the insertion and deletion of different characters do commute, allowing the algorithm to converge and achieve strong eventual consistency.